JPA
◎ JPA(Java Persistence API)
->자바 진영의 ORM표준으로 인터페이스의 모음이다.
◎ ORM(Object-Relational Mapping)
-> 객체는 객체대로 설계하고 관계형 데이터베이스는 관계형 데이터베이스대로 설계한다. ORM 프레임 워크가 중간에서 매핑한다.
◎ JPA를 사용하는 이유
-> 관계형 데이터베이스를 관리할 때 sql이라는 것을 사용한다. spl은 여러가지 문제점이 있다. JPA를 사용하면 이러한 문제점들을 보완할 수 있다.
◎ SQL 중심적인 개발의 문제점
☞ 반복되는 코드가 많다.
테이블을 하나를 만들면 그에 맞는 CRUD를 다 짜야한다.
☞ 패러다임의 불일치(객체 VS 관계형 데이터베이스)
관계형 데이터베이스는 데이터를 정규화해서 보관이 목표, 객체는 객체 지향 프로그램을 통한 기능들을 사용하여 프로그래밍 하는 것이 목표이다. 서로 지향하는 목표가 다르다.
객체를 관계형 데이터베이스에 저장하려면 객체를 SQL로 변환해야하는데 그러면 SQL을 개발자가 직접 작성을 해야한다.
-> 객체와 관계형 데이터베이스의 차이
1. 상속
객체에는 상속이 있지만 관계형 데이터베이스에는 테이블에는 상속관계가 없다. 따라서 객체의 상속과 유사한 슈퍼타 입/서브타입이라는 것을 이용한다. 하지만 이것을 이용하면 각각 테이블에 따른 SQL을 작성하고 그에 맞는 객체를 생성하는 등의 굉장히 복잡한 과정을 거쳐야한다.
2. 연관관계
-> 객체는 참조를 사용한다. ex) member.getTeam(); / 테이블은 외래키를 사용한다. ex) JOIN ON M.TEAM_ID = T.TEAM_ID
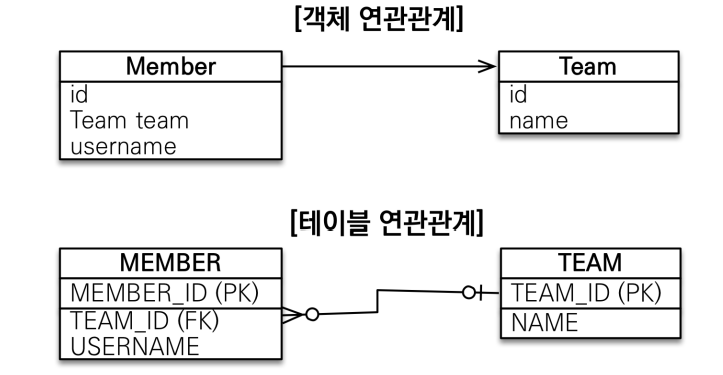
객체 연관관계에서는 Member에서 Team으로 참조로 갈 수 있다. 하지만 Team에서 Member로는 참조가 없기 때문에 갈 수 없다.
테이블 연관관계에서는 MEMBER에 있는 TEAM_ID(FK)로 TEAM에 있는 TEAM_ID(PK)로 갈 수 있고 그 반대로도 갈 수 있다.
이 차이 때문에 객체를 테이블에 맞추어 모델링을 하면 값을 다 세팅해서 저장한 다음 개발자가 직접 연관관계를 설정하고 객체를 반환하는 복잡한 과정을 거친다.
3. 객체 그래프 탐색
-> 객체는 자유롭게 객체 그래프를 탐색할 수 있어야한다.
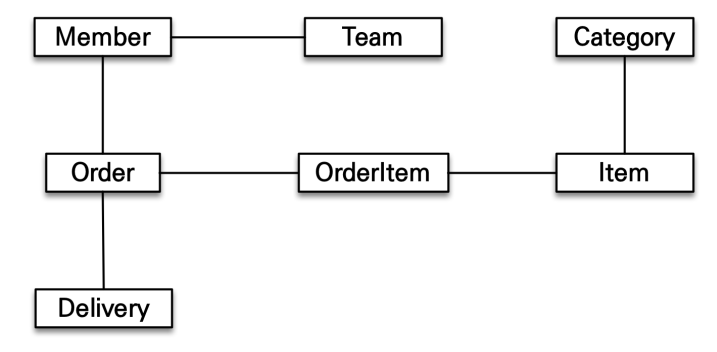
처음 실행하는 SQL에 따라 탐색 범위가 결정된다. 따라서 자유롭게 다른 객체의 값을 사용할 수 없다. 엔티티 신뢰 문제가 발생한다.
-> 엔티티 신뢰 문제
class MemberService{
public void process(){
Member member = memberDAO.find(memberID);
member.getTeam();
member.getOrder().getDelivery();
}
}위 코드의 memberDAO.find(memberID) 어떻게 구성이 되어있는 지 직접 확인하기 전까지는 반환된 멤버 객체를 신뢰하고 사용할 수 없다.
☞ JPA를 사용하면 이런 문제들을 보완할 수 있다.
◎ JPA의 동작방식
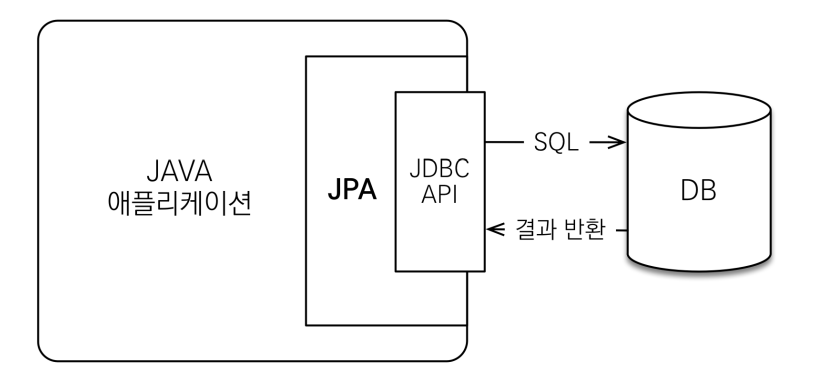
-> jpa는 애플리케이션과 JDBC사이에서 동작한다.
-> JAVA 애플리케이션을 통해 JPA에 명령하면 JDBC API를 사용해서 SQL을 호출한 후 결과를 반환한다.
-> 멤버 객체를 넘기면 JPA가 멤버 객체를 분석하고 적절한 INSERT SQL을 생성하고, JDBC API를 사용해서 DB에 통신하한다.
-> SQL을 개발자가 직접 만드는 것이 아니라 JPA가 만들어 준다.
◎ JPA의 특징
-> 생산성 향상
JPA와 CRUD하는 것이 매우 간단하다.
✔ 저장 : jpa.persist(member)
✔ 조회 : Member member = jpa.find(memberId)
✔ 수정 : member.setName("이름")
✔ 삭제 : jpa.remove(member)
위와 같이 간단한 코드로도 JPA가 알아서 해결한다.
-> 유지보수
수정 사항이 있을 경우 필드만 추가하면 되고 SQL은 JPA가 처리한다.
-> 패러다임 불일치 해결(JPA와 상속, 연관관계, 객체 그래프 탐색)
1. 상속

다음과 같은 관계에서 Album객체를 DB에 저장하려면 jpa.persist(album);만 작성하면 JPA가 INSERT INTO ITEM/ INSERT INTO ALBUM로 두개로 쪼개서 처리한다.
2. 연관관계, 객체 그래프 탐색

위 코드처럼 연관관계를 저장하고 난 후에 자유롭게 객체를 탐색할 수 있다. JPA에서 가져온 member객체를 믿고 사용할 수 있다.
3. 비교하기

◎ JPA의 성능 최적화 기능
-> 1차 캐시와 동일성 보장
String memberId = "100";
Member m1 = jpa.find(Member.class,memberId); //SQL
Member m2 = jpa.find(Member.class,memberId); //캐시
println(m1 == m2); // truememberId를 똑같은 것을 두 번 실행하면 처음 실행할 때는 SQL이 m1을 가져온다. 두 번째 실행할 때는 m1을 그대로 반환한다.
따라서 SQL은 한 번만 실행된다.
-> 트랜잭션을 지원하는 쓰기 지원
트랜잭션을 커밋할 때까지 INSERT SQL을 모아서 JDBC BATCH라는 기능을 이용해 한 번에 SQL을 전송한다.
UPDATE, DELETE로 인한 로우(ROW)락 시간 최소화한다.
-> 지연 로딩 & 즉시 로딩
지연 로딩은 객체가 실제 사용될 때 로딩이 되는 것이다.

TEAM 객체 값을 사용할 때 TEAM 객체 값이 필요한 시점에 JPA가 TEAM에 대한 SQL을 보내 결과를 반환한다.
즉시 로딩은 JOIN SQL로 한 번에 연관된 객체까지 미리 조회한다.

위 코드에서 MEMBER를 조회하면 TEAM을 같이 사용한다면 MEMBER를 조회할 때 JOIN을 사용해 TEAM도 같이 가져온다. 이후에 MEMBER와 TEAM을 조회하면 이미 로딩되어 있는 데이터를 사용한다.
★ 참고 및 자료 출처
자바 ORM 표준 JPA 프로그래밍 - 기본편
https://www.inflearn.com/course/ORM-JPA-Basic/dashboard